Pod Lifecycle
- RNREDDY

- Aug 27, 2025
- 2 min read

Understanding the lifecycle of a Kubernetes Pod is crucial for managing workloads effectively. It helps you anticipate how your applications behave, troubleshoot issues faster, and ultimately ensure smooth deployments in your clusters.
Below is a breakdown of the lifecycle stages that every Kubernetes practitioner should be aware of.
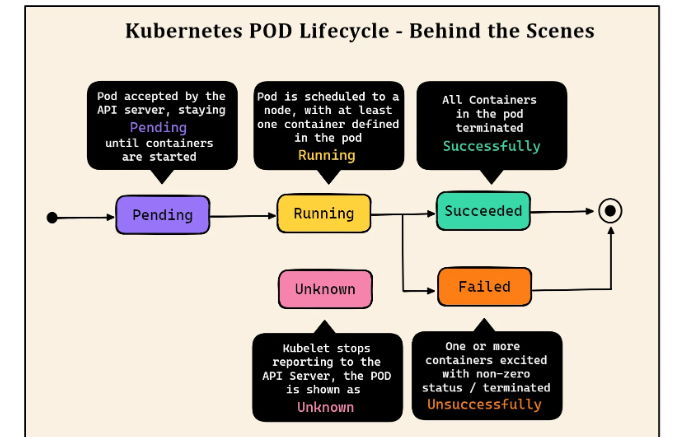
Pending: The Pod is accepted by the API server but remains in a pending state until all required containers start running.
Running: The Pod is scheduled on a node, and at least one container inside the Pod is running.
Succeeded: All containers in the Pod have successfully completed their tasks and exited.
Failed: One or more containers terminated unsuccessfully with a non-zero exit status.
Unknown: Kubernetes has lost communication with the node, and the Pod’s state cannot be determined.
Why It Matters: Understanding these stages allows you to configure more reliable health checks, graceful termination, and better handle failure scenarios like CrashLoopBackOffs.
Pod Fault Recovery and Life Cycle Management
Kubernetes ensures that Pods operate efficiently and can recover from failures. Here’s how:
Single Assignment: A Pod is assigned to a specific node only once during its lifecycle. Once it’s scheduled, the Pod stays on that node until termination or deletion.
Pod Restart Policy: Based on the restart policy (Always, OnFailure, Never), Kubernetes decides whether to restart a failed Pod. For example, if a container within a Pod fails, Kubernetes may attempt to restart it automatically. However, if the Pod cannot recover, it may be deleted, allowing other components to ensure automatic healing.
Failed Nodes: If the node hosting the Pod fails or gets disconnected, Kubernetes considers the Pod unhealthy and eventually deletes it. Kubernetes does not reschedule the same Pod to a new node, but creates a new one if needed.
Takeaway Tips:
Health Probes: Use readiness, liveness, and startup probes to better manage Pod health and avoid unwanted restarts.
CrashLoopBackOff: When Pods fail repeatedly, Kubernetes slows down restart attempts. Investigate logs and events to resolve the root cause.
Graceful Shutdown: Ensure proper shutdown strategies by configuring terminationGracePeriod to allow Pods to exit gracefully before being forcefully terminated.
Final Thought: Pods in Kubernetes are ephemeral by nature, but understanding their lifecycle and how Kubernetes components manage them is key to building resilient, scalable applications.



Comments